Linux, Linux OS, Free Linux Operating System, Linux India Linux, Linux OS,Free Linux Operating System,Linux India supports Linux users in India, Free Software on Linux OS, Linux India helps to growth Linux OS in India
Linux, Linux OS, Free Linux Operating System, Linux India Linux, Linux OS,Free Linux Operating System,Linux India supports Linux users in India, Free Software on Linux OS, Linux India helps to growth Linux OS in India
As Esther Dyson put it, “Using tables to store objects is like driving your car home and then disassembling it to put it in the garage. It can be assembled again in the morning, but one eventually asks whether this is the most efficient way to park a car.”
Applications are getting more complex and dependent on larger quantities of persistent data. Most applications rely on relational databases to manage this abundance of data. However, object databases have become another attractive option for a variety of applications. As Esther Dyson put it, “Using tables to store objects is like driving your car home and then disassembling it to put it in the garage. It can be assembled again in the morning, but one eventually asks whether this is the most efficient way to park a car.” [ORF96]
Object databases got their start in the CAD/CAM world. Object databases support the programmer-defined data types and complex relationships that CAD/CAM applications demand. To manage the additional complexity, object-oriented programming languages are becoming the standard for developing today’s mainstream applications. Using an object database is a natural extension to this language choice. Object databases provide better performance, faster development, and more robust programs. This article examines these claims and looks at a public domain object database, the Texas Persistent Store.
Faster Development and More Robust Programs
Relational databases use a separate programming language, called “Structured Query Language” (SQL). Occasionally, a similar, but non-standard, query language is used to define the layout of the tables and interaction with the database. One shortcoming of relational databases is they can store only a limited set of data types; in order to store objects of more complex types they must somehow be mapped into the primitive types supported by SQL. In contrast, object databases use an object-oriented programming language for data definition and manipulation of the objects within the database. This eliminates the “impedance mismatch” of trying to map your complex objects and relationships into the limited data types and tables of the relational world. The reduction of error-prone translation code lets the programmer concentrate on the semantics of the object’s behavior instead of the syntax of storing and retrieving the object. Without embedded SQL, runtime storage errors are eliminated.
While relational databases must use SQL to recreate these relationships at runtime, object databases capture the inter-object relationships directly in the database. This makes development easier by reducing the lines of codes written and the lines of code executed at runtime. A positive side effect of this is that you will not have to make any design compromises to accommodate join tables or add foreign key identifiers to your classes.
Object databases work on the principle of starting from a named object and navigating to other objects within the class hierarchy. These named objects can be singular objects or containers of objects. Navigation to the contained objects allows an object database to immediately load objects without needing to query. This adds up to less code for the programmer to write and test, making for more robust programs and shorter development cycles.
Increased Performance
If the faster development and more robust programs were not enough to convince you, let’s try increased performance. The goal of many vendors is to make access to persistent objects as fast as access to transient objects. This is an impossible goal because loading a stored object requires accessing a disk and possibly a network. Sophisticated client caching and memory management techniques provide very low overhead once the object is loaded into memory. Some implementations, like the Texas Persistent Store and ObjectStore, have no overhead once the object is swapped into memory. Most relational systems do not cache the results on the client system, thereby incurring unnecessary network transmission and additional queries on the next access.
Unfortunately, there are few current benchmarks that compare relational and object databases to back up these performance claims. There are two common object database benchmarks: the Engineering Database Benchmark—also known as the 001, the Sun Benchmark or the Cattell Benchmark—developed at Sun Microsystems, and the 007 Benchmark, developed at the University of Wisconsin. The 001 Benchmark was intended to prove that object databases out-perform relational databases in engineering applications. The results showed that the measured object databases were 30 or more times faster than the benchmarked relational databases [CAT92]. The 007 tries to provide a broader mix of measurements, including multi-user access. Implementations of the 007 benchmark are audited by the University of Wisconsin and should be available from participating database vendors [LOO95].
Some advanced object database features include clustering and configurable object-fetching policies. Clustering allows programmers to indicate a collection of objects will be used together. All the objects in a cluster are loaded into the client cache when any one of them is requested. This reduces the number of disk and network transfers to load the client cache. Some vendors allow configurable object fetching policies that allows customization of the volume of extra data the server sends along. These performance gains usually come at the expense of increased lines of code and extra performance analysis.
To Swizzle or Not to Swizzle
Object databases come in two models. One requires you to inherit from a vendor-supplied persistent base class, a la the Object Database Management Group (ODMG) standard [CAT96]. The persistent base class provides the interface for making database requests of the objects. The other model is a pointer swizzling technique that allows you to use the pointers to persistent objects as if they never left memory. I believe the pointer swizzling technique is superior in programming model and flexibility, and I will cover this technique in further detail.
Pointer swizzling is the changing or mapping of the on-disk format pointer to the in-memory format pointer. Swizzling of pointers takes place transparently to the client program. When the program uses a pointer to an unloaded object, a segmentation violation occurs. The vendor library traps that violation and fetches the object from the database. It then sets the pointer to the newly loaded object and returns control to the client program. The client program is totally unaware that a database access occurred.
The use of standard C++ memory management techniques allow the same application code to work on both transient and persistent objects. Objects are constructed using the C++ placement new operator. Allocation in persistent memory implicitly stores the object in the database. Removing objects from the database is as simple as calling the C++ delete operator.
The Texas Persistent Store
The Texas Persistent Store is a public domain pointer swizzling object database for C++. Texas was created and is maintained by the University of Texas at Austin. The current 0.4 beta release supports the Linux 1.2.9, Solaris 2.4, SunOS 4.1.3, and DEC Ultrix 4.2 platforms, all using the GNU g++ 2.5.8 or g++ 2.6.3 compiler. It also supports OS/2 2.1 using the IBM CSet compiler and the Sun 3.0.1 C++ compiler. White papers and the source are available via anonymous ftp from cs.utexas.edu, in the directory /pub/garbage, or from the OOPS Research Group’s home page at www.cs.utexas.edu/users/oops.
My setup consists of Slackware 1.2.8 running on a 486/100 with 16Mb of memory. Texas installed and ran on my Linux machine with minimal hassle. Due to a compiler template bug in g++ 2.6.3, you must patch the compiler or modify the makefiles to use the -fexternal_templates compiler switch. The documentation describes both the bug and the fixes, making the library installation fairly painless. Texas comes with a few test programs and examples to ensure the system is performing correctly.
Texas Features
To start coding using the Texas library, you have to understand only four easy features: the initialization macros, opening and closing the persistent stores, finding and creating named roots, and allocating objects into persistent memory. Here, I discuss each of these features briefly and then jump in and look at some code.
Initialization of the Texas library takes place by invoking the TEXAS_MAIN_INIT() macro. This macro sets up the signal handler, reading in the schema information and virtual function tables. The TEXAS_MAIN_UNINIT() macro removes signal handlers and resets the system to its previous state.
Use the open_pstore() function to open a database. If the file does not exist, the database is created and opened. Opening a database starts a transaction. You can manipulate the transactions during the lifetime of the program by calling commit_transaction() or abort_transaction(). commit_transaction() will save all of the current persistent objects to disk and start a new transaction, while abort_transaction() throws away all of the dirty pages and starts a new transaction. To close the database use the close_pstore() function. This implicitly calls commit_transaction() and closes the file database. If you do not want to commit the current work you can call the close_pstore_without_commit() function.
Named roots are your entry points for retrieving the persistent objects from the database. They provide the mechanism by which a program can directly navigate to objects or search containers for objects. You create a named root by using the add_root() function. A named root is retrieved with the get_root() call and the database is queried for the existence of a named root with the is_root() function.
The Texas memory allocation macros, pnew() and pnew_array() hide the C++ placement operator new. The allocation macros also hide the instantiation of the TexasWrapper template classes. The TexasWrapper class handles the creation and registration of schema information with the database. The schema information holds the layout of the class attributes while in the database.
Hello Persistent World
Let’s take a look at an example of how easy it is to make things persistent in Texas. Sticking with tradition, we write the familiar “hello world” program, but with a persistent twist: we record how many times the program has been executed. Listing 1 shows the code for this task.
Listing 1. Hello Persistent World
#include "texas.hh"
#include <stream.h>
PStore* ps = 0;
int main(int argc, const char **argv) {
TEXAS_MAIN_INIT(argc, argv); // initialize the Texas lib
ps = open_pstore("hello.pstore"); // open the persistent store
int* count = 0;
if (!is_root(ps, "COUNT")) { // does a named root already exist?
count = pnew(ps, int)(0); // create a new persistent integer
add_root(ps, int, "COUNT", count); // add a named root
} else {
count = get_root(ps, int, "COUNT"); // get the named root
}
(*count)++;// increment count
count << "Hello Persistent World " << *count << endl;
close_pstore(ps); // close the persistent store, committing
TEXAS_MAIN_UNINIT(); // uninitialize the library
return 0;
}
First we initialize the Texas library, passing it the argc and argv arguments from main. The program then opens up a persistent store named “hello.pstore” in the current working directory.
The persistent store is queried to see if a named root “COUNT” exists using the is_root() function. If the named root does not exist, allocation of a new integer takes place. The new integer is initialized to zero and named “COUNT” using the add_root() function. Otherwise, we retrieve the integer from the database. The counter is incremented and the results printed to standard output. All the dirty objects are committed and the database is closed. The library is uninitialized and the program exits.
With each successive run of the program, the integer named “COUNT” will be retrieved, incremented and rewritten to the database. You will notice this is all quite seamless: there are no explicit calls to queries, inserts, loads, or saves.
Pointer Swizzling Examined in Texas
Next, we briefly explore how Texas swizzles pointers at page fault time and handles memory management. This is by no means a complete discussion of these topics. Readers interested in learning more about the Texas system should download the white papers and source code.
Texas uses conventional virtual memory access mechanisms to ensure the first access of any persistent page is intercepted by the Texas library. This page is loaded from the database and scanned for persistent pointers. Swizzling to in-memory addresses occurs on all persistent pointers on that page. All new pages are reserved and access protected. This faulting and reserving process repeats as the program traverses the object hierarchy of unloaded pages. The pages of virtual memory are reserved one step ahead of the actual referencing page. This implies the program can never see a swizzled pointer, only access protected pointers to unloaded objects. The Linux implementation uses the mprotect() system call to set up the access protection on the pages. An in-depth discussion of this topic can be found in the Texas white paper presented at the Fifth International Workshop on Persistent Object Systems [SIN92].
Texas allows you to access multiple databases, each with its own persistent heap. The standard transient heap and stack are also available for non-persistent memory allocation. Texas does not partition its address space into regions, allowing pages from different heaps to be interleaved within memory. Each page must belong only to a single heap, so Texas maintains separate free lists for each heap. A new page is created when the free list is empty or no free memory chunk available is large enough. New pages are partitioned into uniformly sized memory chunks large enough to hold the object being allocated. All of the other chunks are linked onto the free list. This uniform chunking of a page makes for trivial identification of the object headers on the page. Only the first header of a page needs to be examined to determine the size of all memory chunks on that page. The alignment of the other object’s headers follows trivially. The object’s header stores the schema information for the object so it can be identified and correctly swizzled.
A More Complex Example
While the Hello Persistent World program is not very exciting, it shows the minimal effort needed to make an object (an integer in this case) persistent. The next example demonstrates the power of object databases to capture the relationships between objects. This contrived example shows several many-to-many relationships. It also exposes some of the current deficiencies in the Texas library. The example is a system to track the many different research papers and books that clutter my office. See Figure 1 for a class diagram using non-unified Booch notation. The design file and the source code for both examples are available on my home page at www.qds.com/people/gmeinke.
Figure 1: Booch Class Diagram of a Published Work Tracking System
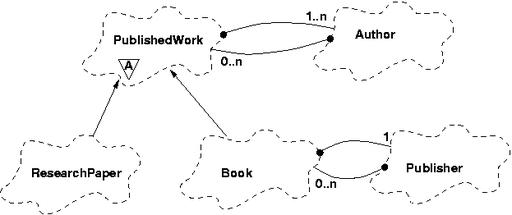
The class diagram shows class PublishedWork, an abstract base class for all published material. It presents trivial methods for querying the object for its title, price, the number of pages, and a list of authors. The relationship between an Author and their PublishedWork is an example of a many-to-many relationship. The relationship between a Publisher and the Books they have published is one-to-many. Expressing these complex relationships in relational databases is awkward due to the foreign keys and the intermediate join table needed for the many-to-many relationships. By contrast, Texas handles these complex relationships with C++ containers and stores them directly in the object database. No compromises are necessary to the object design for foreign key data members.
Current Limitations and Future Work
Current limitations of the Texas library include the lack of multi-user support and the inability to query containers to find certain instances of objects. The query limitation stems from the fact that there are no containers provided with the Texas library. Most commercial object database vendors provide a set of optimized container classes that support queries. These limitations are minor if what you need is a very fast, single user, persistent store of objects. Another limitation is the inability to treat persistent and transient objects transparently. You cannot discover what heap an object is allocated on; this causes problems in objects with pointers to other contained objects. While this is a minor limitation for smaller programs, it does affect development of larger, more complex, multiple-database programs.
The future of Texas looks bright. It is a robust and efficient single user, portable library. A colleague and I are planning to port Texas to Windows NT. This will round out support for the most popular platforms, Solaris, Linux, and NT. We also plan to provide minor enhancements for the transparent treatment of the heaps. STL and a persistent allocator may provide some relief for lack of container and query support, but multi-user support is still off in the future.
Conclusions
Object databases are not the silver bullet of software development, but they do provide a more robust and natural programming environment for people already using an object-oriented programming language. They provide better performance and more performance tuning options than relational databases. For small to medium sized single-user projects, the Texas database is an attractive choice; for larger multi-user projects, you may want to check out ObjectStore from Object Design, Inc. ObjectStore supports a large number of platforms and compilers—unfortunately, not Linux. ObjectStore is a very fast and flexible object database product. For more information on ObjectStore, visit their home page at www.odi.com or subscribe to the ObjectStore development mailing list. (To subscribe, send e-mail to ostore-request@qds.com with no subject and subscribe in the message body.)
Special thanks to Rob Murray of Quantitative Data Systems and Craig Heckman of Superconducting Core Technologies for their great comments and help.
[ORF96] Robert Orfali, Dan Harkey, & Jeri Edwards, The Essential Distributed Objects Survival Guide, John Wiley & Sons, Inc. pp. 164, 1996. [CAT92] R.G.G. Cattell, and J. Skeen. Object Operations Benchmark, ACM Transactions on Database Systems,17(1):1-31, 1992. [LOO95] Mary E. S. Loomis, Object Databases: The Essentials, Addison-Wesley Publishing Company, pp. 197-200, 1995. [CAT96] R.G.G. Cattell, The Object Database Standard: ODMG – 93, Release 1.2, Morgan Kaufmann Publishers, Inc., 1996. [SIN92] Vivek Singhal, Sheetal V. Kakkad, and Paul R. Wilson, Texas: An Efficient, Portable Persistent Store, Fifth International Workshop on Persistent Object Systems, 1992.Object Databases: Not Just for CAD/CAM Anymore.